- Data Science
- Molecular structure / Affinity / Solubility
- Materials Science
- Life Science
[Analysis Example] Estimation of the χ parameter by machine learning
Creating features from descriptors of two molecules and learning the relationship with the interaction parameter χ
Objectives and Methods
The J-OCTA machine learning function (MI-Suite) was used to estimate the χ parameter. The data used was obtained from Flory-Huggins Chi Database. The data obtained were the names of two compounds A and B and the value of the χ parameter between them. The number of data was 263. The procedure for learning/predicting the χ parameters was as follows;
- χ Parameter learning/prediction procedure
-
- 1. The SMILES representation of each compound was obtained from PubChem, a public compound database.
The data was obtained using DB-Explorer, a data acquisition function of MI-Suite. Only compound pairs (169) for which SMILES expressions for both A and B were obtained were used. - 2. Descriptor values, AutoCorr3D for each compound were calculated using the descriptor calculation function ChemDC.
- 3. The calculated values of the descriptors were mixed according to the description of the compound pair in the original data to create a single feature.
The mixing scheme used was the mixing scheme used in quantitative geography, since the descriptor (AutoCorr3D) can be regarded as a spatial autocorrelation quantity. - 4. The training was performed with the mixed calculated features as input values and the χ parameter of each compound pair as the objective value.
The settings for learning were as follow;
- - Among the learning methods supported by MI-Suite's learning function, we used XGBoost, a boosting-based learning method. the hyperparameters of XGBoost are set based on GP (Gaussian process) for optimal parameter settings.
- - Outlier removal was performed at the 90th percentile point (both sides).
- - The data ratio of the training and test sets during training was 8:2.
- 1. The SMILES representation of each compound was obtained from PubChem, a public compound database.
Results
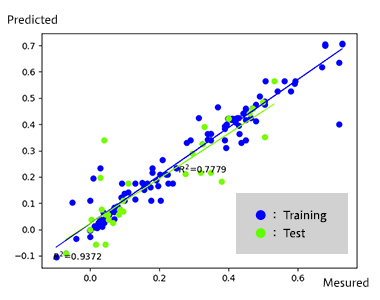
The results of the training are shown below.
For the prediction model obtained by training (i.e., learned model), the prediction accuracy when using the training set was R^2=0.937 on a coefficient of determination basis, while the prediction accuracy when using the test set was R^2=0.778.
- Related Functions
- MI-Suite (Materials Informatics Suite)